“It is literally the case that learning language makes you smarter. ”
前言
最近开始接触神经网络,遂记下自己学习过程中遇到的问题和心得。 简单来说:人工神经网络是一种旨在模仿人脑结构及其功能的信息处理系统。 人工神经网络的整个发展过程,大致可以分为5个阶段:
- 形成时期,M-P模型
- 低谷时期,当时神经网络只能训练单层
- 复兴时期,Hopfield模型
- 发展时期,BP算法的提出导致了DNN的发展
- 繁荣时期,各种深度网络的提出
更详细的解释可以参考人工神经网络的发展及应用。本文的学习路线及符号表示方法均来自于UFLDL Tutorial,有英文版和中文版。
正文
初识神经网络
神经网络,顾名思义,来自于人的神经系统,其基本单位是神经元,神经元的作用是传递信息和处理信息,神经网络 正是利用这个特点完成分类和回归的功能。 传递信息,类似于人通过眼睛,鼻子,耳朵等感受到外界的刺激,最终被送到大脑。 处理信息,类似于人看到一只动物,能够判断这是猫还是狗。 而基本神经元可以抽象成Logistic Regression,其中比较巧妙的是设置了一个非线性激活函数,这个激活函数把 $\mathbb{R}$ 映射到$\left [ -1,1 \right ]$区间,这为拟合更复杂的函数提供了可能,也能够在保证分类效果的前提下提高容错性。 基本单位神经元可以表示为
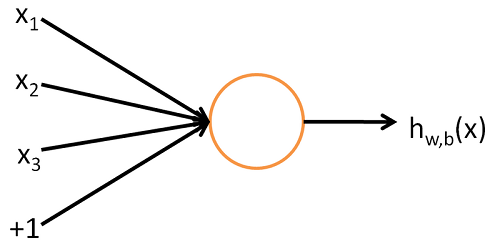
神经元的输入是自变量,通常可以表示为向量的形式,向量中每个元素$x_{i}$表示特征的某一维度,通常还会增加一项偏置项+1, 每个特征的线性加权和构成这个神经元的总输入,同时还需要一个非线性激活函数,以sigmoid函数 $f\left ( z \right )=1/(1+exp(-z))$ 为例,那么神经元的输出就是
之所以采用sigmoid函数,是因为它有非常好的性质:非线性,连续可导,一阶导数可以表示为 ${f}’\left ( z \right )=f\left ( z \right )\left ( 1-f\left ( z \right ) \right )$,一阶导数在x=0处取得最大值。 类似的其他非线性激活函数还有双曲正切函数:
神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入,实现了信息在网络内部的传递。 一个简单的神经网络可以表示为下图
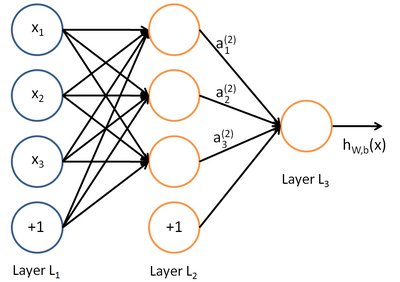
我们使用圆圈来表示神经网络的输入,标上”$+1$”的圆圈被称为偏置节点(bias units),也就是截距项。神经网络最左边的一层叫做输入层(input layer),最右的一层叫做输出层(output layer)(本例中,输出层只有一个节点)。在输入层与输出层中间是隐藏层(hidden layer),之所以称为隐藏层是因为这些结点的值在训练集中不可见,并且也不能作为输出观察到,只是作为中间变量辅助训练参数。上图的神经网络有3个输入,3个隐藏和1个输出。
除了输入层以外,其他层的输入是上一层所有结点的输出的线性加权和,这个所谓的权值就是我们的神经网络需要训练的参数,用$W$和$b$来表示。输入经过激活函数的非线性变换作为当前结点的输出。上图神经网络中各神经元的输入输出表示为:
这个从输入到输出的过程也称为前向传播。我们用$z$表示激活函数f的自变量,也就是当前节点的输入。那么隐藏层任意一个结点的输入可以表示为$z_i^{(2)}=\sum_{j=1}^{n}W_{ij}^{(1)}x_j+b_i^{(1)}$,输出表示为 $a_i^{(2)}=f(z_i^{(2)})$。
反向传播算法
反向传播是梯度下降算法在神经网络中的应用,也是导致神经网络进一步发展的创新方法。与前向传播相对应反向传播是从输出相输入进行传播,这个传播过程传递的是梯度,而梯度用来计算各层权重$W$和$b$。残差的计算分为两部分,一部分是输出层的残差,另外是隐藏层的残差。所以,对于批量梯度下降算法,在进行反向传播之前,先要进行一次前向传播。具体公式的推导已经在教程中详细解释了,这里只把结果重述一下:
有了残差,权重参数的梯度计算公式就表示为:
这样就可以根据批量梯度下降法来根据所有样本更新参数矩阵了。一个多层全连接神经网络就产生了。